Comprehensions and Generators
Contents
Comprehensions and Generators 1#
Collections of Data#
Comprehensions and generators are ways of transforming collections of data. So, let us first look at such data collections.
A collection of data can be stored in a tuple, list, set, or dictionary. The difference between using one or the other will depend on the properties you need to represent your data. In the following table, we briefly present the properties of each of these collections.
Collection |
Mutable |
Ordered |
Allows duplicates |
Indexed |
Representation |
|---|---|---|---|---|---|
|
✖︎ |
✔︎ |
✔︎ |
✔︎ |
|
|
✔︎ |
✔︎ |
✔︎ |
✔︎ |
|
|
✔︎ |
✖︎ |
✖︎ |
✖︎ |
|
|
✔︎ |
✖︎ |
✖︎ |
✔︎ * |
|
* You access key-value pairs via a key.
Additionally, we have already seen a number of built-in operations on lists, such as
indexing, to access an item at a given index:
s[i], where0 <= i < len(s)slicing, to extract a subsequence of items:
s[a:b]extracts the list ofs[i]witha <= i < b, ors[a:b:c]wherecis the step sizeconcatenation:
s + tlength:
len(s)aggregation:
sum(s),min(s),max(s)sorting:
sorted(s)
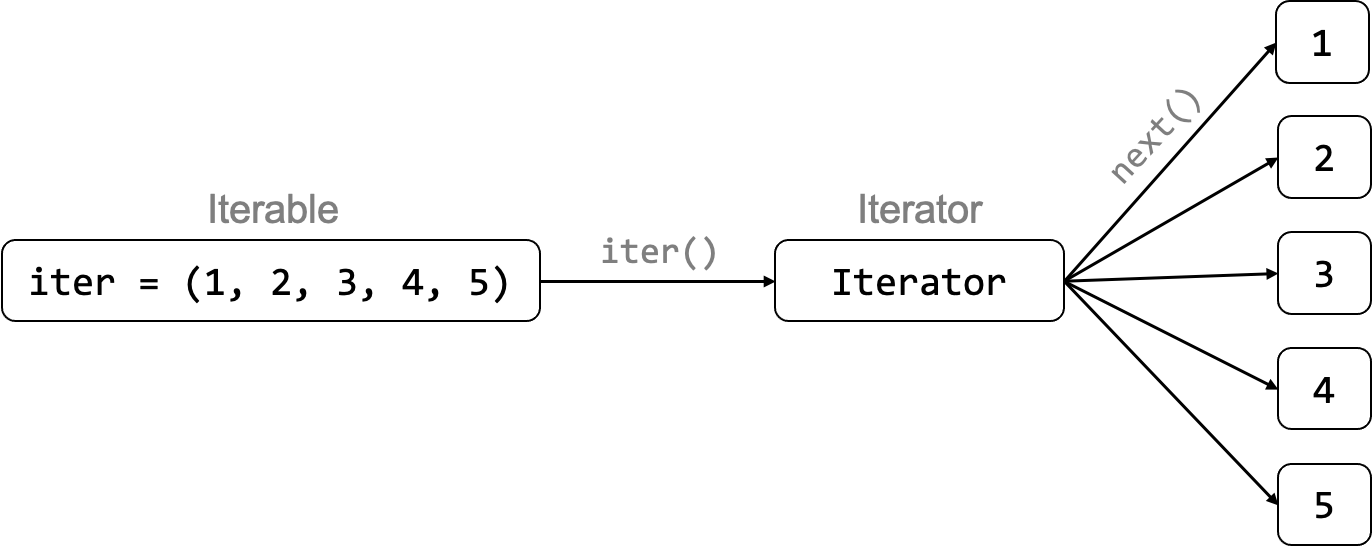
Iterables and Iterators#
What collections of data have in common is that they are iterable.
An iterable is any collection that you can step through one by one.
To traverse an iterable you require an iterator.
An iterator is an object that traverses your iterable and returns one element at a time.
To transform a collection into an iterator, we use the iter() method.
Afterwards, each element in the iterator can be accessed by repeatedly calling the next() method.
# Create a list of integers, which is an iterable
iterable: list = [1, 2, 3, 4, 5]
print(type(iterable))
iterable
<class 'list'>
[1, 2, 3, 4, 5]
from typing import Iterator
# Create an iterator out from the "iterable" list
iterator: Iterator = iter(iterable)
type(iterator)
list_iterator
# Traverse the iterable via the iterator
num_one = next(iterator)
print(f'First iteration: {num_one}')
num_two = next(iterator)
print(f'Second iteration: {num_two}')
num_three = next(iterator)
print(f'Third iteration: {num_three}')
num_four = next(iterator)
print(f'Fourth iteration: {num_four}')
num_five = next(iterator)
print(f'Fifth iteration: {num_five}')
First iteration: 1
Second iteration: 2
Third iteration: 3
Fourth iteration: 4
Fifth iteration: 5
If the collection has been traversed and you call the next() function one more time, you will get a StopIteration error.
next(iterator)
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[4], line 1
----> 1 next(iterator)
StopIteration:
Let us now use the while loop to iterate over our iterable in a smarter way.
iterable: list = [1, 2, 3, 4, 5]
iterator: Iterator = iter(iterable)
i: int = 0
while i < len(iterable):
val: int = next(iterator)
print(val)
i += 1
When using a for loop, you do not need to call these methods. The previous procedure is done under the hood by Python!
Furthermore, one iterable can be iterated over or traversed multiple times. Each new traversal involves a new iterator. In fact, multiple iterators can be active concurrently on the same collection, as it is the case of nested loops.
letters: tuple = ('a', 'b', 'c')
for i in letters:
for j in letters:
print('{}{}'.format(i, j), end=" ")
print()
Do It Yourself!
Iterate over the list of words and add the words that start by ‘a’ to a new list.
words = ['age', 'bee', 'ask', 'cut', 'clean', 'zoo', 'add']
# Remove this line and add your code here
Comprehensions#
A list comprehension is an expression that constructs a list based on some iterable. The items taken from the iterable can be transformed in an expression before being collected in the list.
In the next example, the iterable is range(10), and we collect the squares of the numbers in that range:
[n * n for n in range(10)]
The list comprehension above defines the same list
as the following program fragment
with a for statement and an auxiliary variable (aux), but in a more compact way.
aux: list = []
for n in range(10):
aux.append(n * n)
aux
The comprehension is more compact, and does not need an explicit list variable.
Do It Yourself!
Use a comprehension to create a list where all words in the given list are transformed into capital letters.
words = ['age', 'bee', 'ask', 'cut', 'clean', 'zoo', 'add']
# Remove this line and add your code here
Selective Inclusion in a Comprehension#
You can also selectively include items in the constructed list,
by using an if clause.
For instance, the numbers less than 10
that leave a remainder more than 2 when divided by 7:
[n for n in range(10) if n % 7 > 2]
And here is the list of squares of those numbers that leave a remainder more than 2 when divided by 7.
[n * n for n in range(10) if n % 7 > 2]
Note that the condition is applied to the items before they are transformed.
This is like putting an if statement inside the for loop.
aux: list = []
for n in range(10):
if n % 7 > 2:
aux.append(n * n)
aux
In summary, a list comprehension
[E(v) for v in iterable if C(v)]
takes items from an iterable:
for v in iterable
selects items based on a condition:
if C(v)
transforms the selected items using an expression:
E(v)
and collects the expression results in a list:
[...]
Note the order: first select, then transform (even though you write the transformation first, and the selection last).
Do It Yourself!
Remember our fisr exercise in this notebook? Use a comprehension to iterate over the list of words and add the words that start by ‘a’ to a new list.
words = ['age', 'bee', 'ask', 'cut', 'clean', 'zoo', 'add']
# Remove this line and add your code here
Nested Comprehensions#
If you need to select after transforming the items, then you can use a nested comprehension (but do read the warning after the following example).
[sq for sq in [n * n for n in range(10)] if sq % 7 > 2]
Observe that the result is different with [n * n for n in range(10) if n % 7 > 2], why?
Warning
In a nested comprehension, the inner comprehension is completely evaluated and stored before it is being used in the outer comprehension.
Do It Yourself!
We have a list of lists. The internal lists have numbers as elements. We would like to flatten the outer list; i.e. instead of have lists of lists of numbers we just want to have a list of numbers. Use a nested comprehension to achieve this goal.
lst = [[1, 2, 3], [4, 5, 6, 7], [8, 9, 10], [11], [12, 13, 14, 15]]
# Remove this line and add your code here
Alternative Approaches for Selection After Transformation#
Perfom the transformation (in this case: squaring)
also in the if clause:
[n * n for n in range(10) if n * n % 7 > 2]
A disadvantage of this approach is that every transformation is done twice, which can be costly if the transformation is expensive.
Set and Dictionary Comprehensions#
Comprehensions can involve multiple
forandifclauses (but always start with an expression and aforclause).
Here are some examples. The set of non-prime numbers up to 100:
composites: set = {i * j for i in range(2, 10 + 1) for j in range(2, 100 // i + 1)}
composites
Let us decompose this rather complex comprehension by looking what each step does, both as list and set.
[i for i in range(2, 10 + 1)]
{i for i in range(2, 10 + 1)}
Let us add the second comprehension and first see the result when a list is being returned.
[j for i in range(2, 10 + 1) for j in range(2, 100 // i + 1)]
{j for i in range(2, 10 + 1) for j in range(2, 100 // i + 1)}
Do It Yourself!
We would like to use a set comprehension to create a set with all words of length 4 that are part of a given list. Remember that sets do not have duplicates and that is why we eant to use them as data type.
lst = ['funny', 'that', 'little', 'yoke', 'sunny', 'side', 'up', 'in', 'the', 'span',
'of', 'the', 'lake']
# Remove this line and add your code here
A dictionary that associates the numbers 13 through 32 to their squares:
squares: dict = {n: n * n for n in range(13, 32 + 1)}
squares
A list of powers
where the base is a prime less than 10 and
exponents run from 2 through 5
(it uses composites defined earlier);
note the clause order for if for:
[base ** exp for base in range(2, 10 + 1) if base not in composites for exp in range(2, 5 + 1)]
In order to understand it may be again helpful to look at the individual results of each comprehension.
Do It Yourself!
Use a comprehension to create a dictionary that stores the words within the list lst as keys and tehir length as values.
lst = ['funny', 'that', 'little', 'yoke', 'sunny', 'side', 'up', 'in', 'the', 'span',
'of', 'the', 'lake']
# Remove this line and add your code here
Comprehensions Evaluation#
Comprehensions are completely evaluated before further use.
What if you do not need the whole list constructed by the comprehension? Suppose, for instance, you only want the first element. Will the whole list still be computed?
To illustrate what we mean,
we first show a version with explicit
for, if, and break statements,
that avoids computing all values in the list.
It stops when the first item has been computed.
aux: list = []
for n in range(10):
if n % 7 > 2:
aux.append(n * n)
break
print(aux)
aux[0]
Let’s try this with our comprehension, by extracting the first item (at index 0).
[n * n for n in range(20) if n % 7 > 2][0]
Actually, we now cannot see whether the whole list got computed.
So, let us introduce a function f with a side effect
to make this visible.
A side effect is the modification of any sort of state such as changing a mutable variable, using IO, or throwing an exception.
As a function, trail does nothing to its argument:
it returns n unchanged.
But it also prints a dot, and this is a (visible) side effect.
from typing import Any
def trail(n: Any) -> Any:
""" Print a dot and return n.
"""
print('.', end='')
return n
Let us try again.
[trail(n * n) for n in range(20) if n % 7 > 2][0]
Apparently, the whole list got computed first.
Generators#
We can fix this by using a generator.
A generator expression is like a comprehension: it selectively takes items from an iterable and transforms them.
But a generator does not construct a list to store all items.
A generator is lazy, in the sense that a generator will not be computed completely in advance. (In fact, a generator can be endless/infinite.)
Instead, a generator is only evaluated to the extent that its values are needed. The evaluation of a generator is demand driven.
A generator is not a list, but it is itself again an iterable. In fact, a generator is an iterator. (A list is also an iterable, but a list is completely stored in memory.)
Let us define a function first
that will only extract the first element of an iterable.
(We need this function first,
because we cannot extract the first item from an iterable by indexing it at 0,
like we did with the list comprehension.)
from typing import Iterable
def first(iterable: Iterable) -> Any:
""" Returns first item from iterable.
"""
for item in iterable:
return item # and ignore everything else
If we apply this to the list comprehension, we (again) see that the whole list still gets computed.
first([trail(n * n) for n in range(20) if n % 7 > 2])
Now, let us apply it to the generator version of the comprehension. Note the use of round parentheses instead of square brackets. By the way, since the function call also involves round parentheses, we don’t have to repeat another pair.
first(trail(n * n) for n in range(20) if n % 7 > 2)
We see that now only one item got computed (the first one).
Do It Yourself!
Create the function first_multiple_of_2 which gets an iterable as argument and returns the first number that is multiple of two. Build a generator that iterates over number from 1 to 10, and computes the result of multiplying a given number by 3.
# Remove this line and add your code here
A Generator Can be Used Only Once#
Because a generator is a (special kind of) iterator, it can be used only once.
Let us store our generator in a variable:
my_gen = (trail(n * n) for n in range(10) if n % 7 > 2)
You can then use this variable as an iterable.
first(my_gen)
for i in my_gen:
print(i, end=" ")
Observe that the generator continued where it left off after its first (partial) use. Once a generator is exhausted (has reached the end), it becomes useless.
for i in my_gen:
print(i, end=" ")
(There is no output, because the generator was already exhausted.)
Factories#
Since generators (like iterators) are not reusable, it is more common to define a function that returns a fresh generator on each call. Such a function is also known as a factory. If that function is parameterized, then you can produce customized generators.
Here is an example of a parameterized factory:
from typing import Generator
def square_factory(m: int) -> Generator[int, None, None]:
""" Returns a generator for the squares of numbers in the range [0, m).
"""
return (n * n for n in range(m) if n % 7 > 2)
The call square_factory(10) returns (a fresh copy of) the generator
that we considered above.
Let’s try the same things again, using this factory.
first(square_factory(10))
for i in square_factory(10):
print(i, end=" ")
print()
for i in square_factory(10):
print(i, end=" ")
That looks better.
The for loop starts all over again.
Do It Yourself!
Create a factory function to return the generator you created before: the one related to computing the multiplication of a number by 3.
# Remove this line and add your code here